


The models, evaluation, difference from GPT-4 and its possible limitations

What the Gemini…
Gemini is a multimodal model developed at Google, using the Transformer architecture to process variable-length input sequences of text, images, audio, and video. It is designed to handle multiple data types simultaneously, unlike previous models that used separate models for different data types. Gemini uses a shared Transformer backbone with modality-specific input and output heads, allowing it to leverage shared reasoning capabilities while processing and generating specific data types. It comes in three sizes: Ultra for complex tasks, Pro for scalable performance, and Nano for on-device efficiency. The model excels in tasks ranging from understanding individual modalities to complex reasoning across multiple data types.
More practically
For mortals out there, Gemini models are like really smart computers that learn from different things like words, pictures, sounds, and videos. They get this information from many places, like news articles, books, websites, social media, movies, and music. This mix of information helps them understand and do lots of different tasks.
When Gemini models learn from words, they break the words into smaller pieces, we call them Tokens. It’s like cutting a sentence into individual words or even smaller parts. This helps the computer understand the meaning better.
For pictures, the models make all the pictures the same size and adjust the colors. This way, they can understand any picture, regardless of its original size or color depth.
Sounds are turned into a special kind of picture that shows how the sound changes over time. This helps the computer see the sounds and understand them.
Videos are made into a series of pictures, and each picture is treated like a regular image. This helps the computer understand what’s happening in the video as time goes on.
It’s important to prepare all this information well and use lots of different types so that the computer can learn to do many things.
What about their evaluation?
The models are put through different challenges to check their understanding and creation abilities in each area. They’re compared to other advanced models to see where they excel and where they can improve. The tests also look at how the models could be used in real life, like summarizing documents or understanding complex tasks with different types of information. The report talks about the limitations of some tests and suggests ideas for future improvements. This chapter highlights the importance of thorough testing in developing and understanding advanced AI models like Gemini.
What is it capable of?
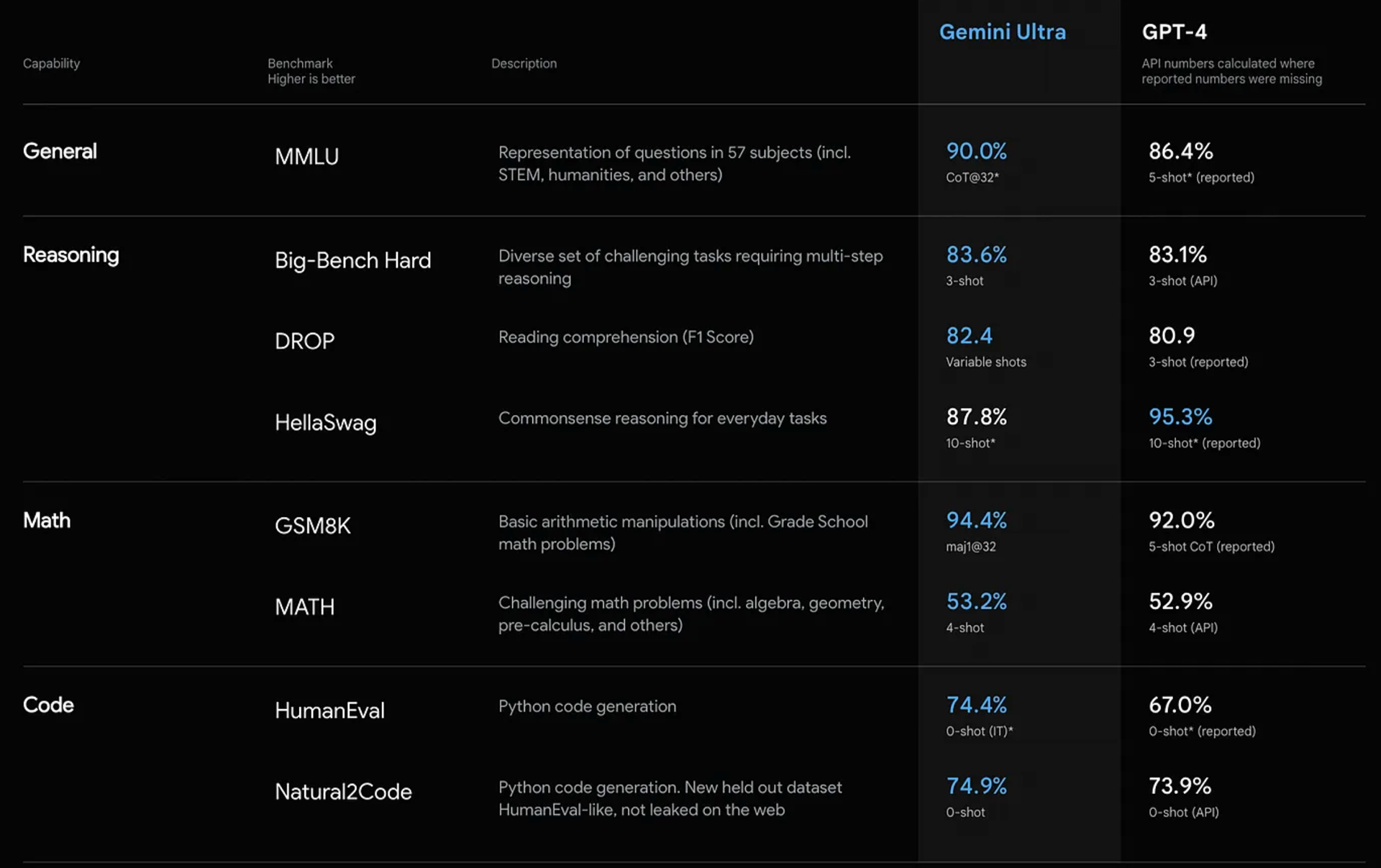
Gemini model family has been evaluated on more than 50 benchmarks in six different capabilities. Some of the most notable benchmarks were discussed in the last section. The capabilities are:
Factuality: This capability covers open/closed-book retrieval and question answering tasks. It assesses the model’s ability to retrieve and present factual information accurately.
Long-Context: This includes tasks for long-form summarization, retrieval, and question answering. It tests the model’s ability to handle and process information from extended text passages.
Math/Science: This category includes tasks for mathematical problem solving, theorem proving, and scientific exams. It evaluates the model’s proficiency in handling mathematical concepts and scientific knowledge.
Reasoning: These tasks require arithmetic, scientific, and commonsense reasoning. It challenges the model to apply logical and analytical thinking to solve problems.
Multilingual: This encompasses tasks for translation, summarization, and reasoning in multiple languages. It examines the model’s ability to understand and generate content in different languages.
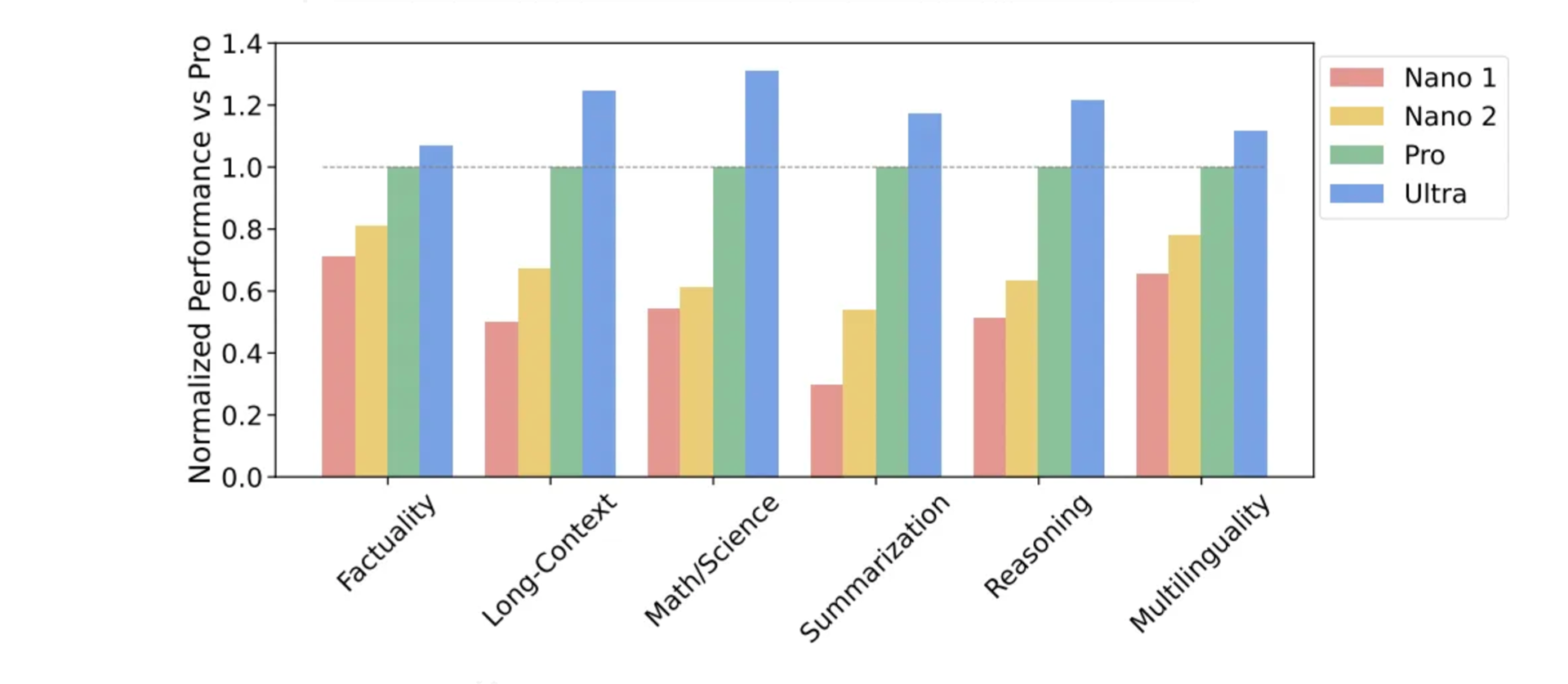
These capabilities demonstrate the model’s versatility and effectiveness in handling a wide range of tasks across different domains and modalities.
Performance
Gemini Nano, a compact and efficient version, is designed for on-device applications, maintaining performance with limited resources. Gemini Pro and Ultra are larger models, with Pro optimized for scalable deployment and Ultra for complex tasks, demonstrating the family’s adaptability to different needs. The multimodal nature of Gemini allows it to handle text, images, audio, and video SIMULTANEOUSLY, enabling complex reasoning across data types.
Understanding Humor in Memes: In one example, Gemini demonstrates its ability to understand humor in memes. The model was presented with a meme about a person playing a game at 300 frames per second (FPS) on a monitor that only supports 75Hz. Gemini successfully interpreted the humor, explaining that the meme is funny because it is relatable to anyone who has played a game on a monitor that is not fast enough to display the game’s FPS. This example showcases Gemini’s ability to not only understand the visual content of the meme but also to grasp the cultural context and the humor behind it.

State-of-the-art performance in various benchmarks underscores the models’ advanced capabilities. Additionally, the chapter explores the models’ efficiency and scalability, highlighting their potential for deployment in diverse environments. This chapter underlines the Gemini models’ potential in transforming AI applications across domains.
Mathematical Problem Solving: Gemini’s ability to tackle complex mathematical problems is highlighted through an example where the model solves a challenging math problem. The model was able to understand the problem’s context, apply the necessary mathematical concepts, and provide a correct solution. This demonstrates Gemini’s advanced reasoning and problem-solving capabilities, particularly in the STEM (Science, Technology, Engineering, and Mathematics) domain.

Responsible Deployment aka emphasizing the importance of ethical and societal considerations in deploying AI models like Gemini
When deploying advanced AI models like Gemini, it’s crucial to consider their ethical and societal impact. Ensuring fairness and inclusivity is key, as is addressing potential risks and biases. Thoughtful guidelines are needed for their deployment, focusing on safe, ethical, and beneficial use. This approach ensures that the impact of these AI models extends beyond technical achievements, contributing positively to society.

5 ways Gemini is different from GPT-4? But, please, explain so we understand…
How It’s Built (Architecture): GPT-4 is mainly good at working with words, like in books or websites. But Gemini can understand words, pictures, sounds, and videos. It has a special part (called a Transformer backbone) that lets it work with all these different types of information together.
What It Learns From (Training Data and Preprocessing): Gemini learns from a mix of words, pictures, sounds, and videos, while GPT-4 mostly learns from words. Before Gemini starts learning, it prepares all these different types of information so it can understand them better.
What It Can Do (Multimodal Capabilities): Gemini can handle tasks that use different types of information at the same time. For example, it can look at a picture, read a question about it in words, and then answer in words. GPT-4 mostly works with just words, so it can’t do this as well.
How Well It Does Things (Versatility and Task Performance): Gemini is really good at doing tasks with different types of information, like understanding pictures or sounds and then thinking about them. GPT-4 is great at things to do with words, like translating languages or answering questions, but it’s not made to work with pictures or sounds.
How It’s Used (Efficiency and Deployment): Gemini comes in different sizes for different needs. The smallest size, Gemini Nano, is made to work well on devices like phones. GPT-4 is efficient for a big word-focused AI, but it’s not specially made for use on devices like phones.
In short, Gemini’s ability to work with different types of information and its special design for different needs make it stand out from AI tools that mainly work with words, like GPT-4. This makes Gemini useful for a wider variety of tasks that involve words, pictures, sounds, and videos.
Too Good to be true?
Models like Gemini can have downsides such as their need for a lot of computing power, the cost of training and keeping them up-to-date, concerns about data privacy and security, potential biases in decisions, over-reliance on AI, difficulty in understanding how they make decisions, and their environmental impact due to high energy use.
Acknowledging the limitations
The conclusion of the Gemini report summarizes the advancements and future potential of the Gemini models, while also acknowledging their limitations:
Advancements: Gemini models represent a significant step forward in multimodal capabilities, handling text, code, images, audio, and video. Gemini Ultra, the most capable model, sets new standards in several benchmarks, surpassing human-expert performance in the MMLU exam benchmark and excelling in image, video, and audio understanding without task-specific modifications.
New Use Cases: The models’ abilities to parse complex images, reason over sequences of different modalities, and generate combined text and image responses open up new applications in education, problem-solving, multilingual communication, information summarization, and creativity.
Limitations: Despite their impressive capabilities, the models have limitations. There is a need for ongoing research on “hallucinations” (inaccurate or fabricated content) generated by large language models (LLMs) to ensure more reliable outputs. LLMs also struggle with tasks requiring high-level reasoning, such as causal understanding and logical deduction. This highlights the need for more challenging and robust evaluations to measure their true understanding.
Future Directions: Gemini is part of Google’s broader mission to solve intelligence, advance science, and benefit humanity. The report envisions the development of a large-scale, modularized system with broad generalization capabilities across many modalities, building on Google’s innovations in machine learning, data infrastructure, and responsible development.
Where can we test it?
Access Bard here.